I dati non mentono, ma ciò che ci si può fare risponde tanto a regole scientifiche quanto all’innovazione. Ed è soprattutto quest’ultima a godere dei benefici vicendevoli che Data science e ChatGPT profondono.
ChatGPT è, di fatto, una rete neurale avanzata, ovvero un modello linguistico di grandi dimensioni (LLM) che usa il Deep learning per restituire testo simile a quello prodotto dall’uomo.
Ed è proprio la modellazione linguistica il compito capitale della preformazione, fase durante la quale il modello, facendo leva sulle parole precedenti, individua quelle utili alla sequenza per restituire una frase di senso compiuto e di qualità. In realtà, ChatGPT, fornisce una rappresentazione della frase perché non ne capisce il senso né il contesto. C’è un livello di complessità enorme che, giustamente come ogni tecnologia richiede, è del tutto trasparente a chi ne fa uso.
Indice degli argomenti
Come la Data science sta rivoluzionando l’efficacia di ChatGPT
Argomento che rappresenta la sintesi del rapporto simbiotico tra Data science e ChatGPT e che, per essere approfondito, obbliga a entrare nelle meccaniche di entrambi gli aspetti per scoprirne le dinamiche (e accorgerci di una certa somiglianza).
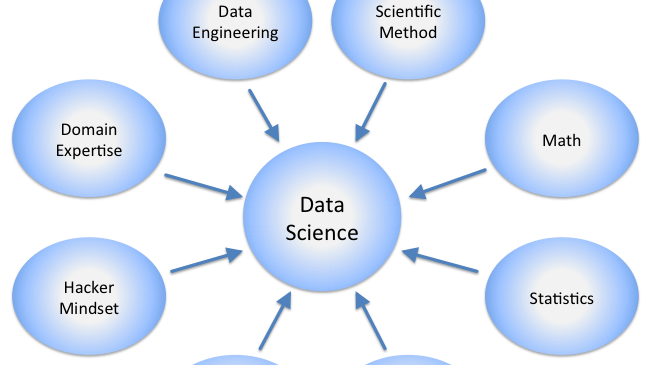
Entrando tra le pieghe della Data Science, si incontrano quattro sottolivelli, ossia:
- scraping: nella sua accezione più ampia e comune, lo scraping è l’estrazione, mediante un software, di dati da un output generato da altri software. La forma più tipica è quella del web scraping, ossia l’estrazione di informazioni da uno o più siti web e può essere fatto in diversi modi, le principali librerie Python utili sono Scrapy e Beautifulsoup (per citarne due)
- esplorazione e analisi: i dati devono essere analizzati e, anche in questo ambito, ci sono librerie note quali, tra le tante, Numpy, Pandas e Scikit-learn
- visualizzazione: i dati devono poi essere resi comprensibili, restituendo una rappresentazione grafica che possa essere capita dai vertici aziendali o dalla platea di riferimento. Oltre alle librerie Python (Matplotlib è forse la più diffusa) ci sono strumenti terzi che facilitano il compito
- Machine learning: tutte attività necessarie a scoprire modelli, apprendere e fare previsioni
Questi sono quattro ambiti nei quali ChatGPT eccelle. Non si spinge soltanto fino al punto di aiutare i modelli Machine learning ad apprendere e di conseguenza a fare previsioni più accurate, con le appropriate tecniche di prompting crea visualizzazioni interattive, fa lo scraping di dati dal web e si presta all’analisi dei dati per trovare correlazioni.
È evidente come, pure essendo due mondi simbiotici, il progredire della Data Science contribuisca ad affilare le lame di ChatGPT e viceversa. Il fascino di due emisferi che ne formano uno solo.
Data science e ChatGPT: l’intelligenza artificiale al servizio dell’analisi dei dati
Altro tema che si snoda attraverso alcuni punti capitali, perché ChatGPT assiste i data scientist in diversi aspetti del loro lavoro. Tra questi:
- ottimizzazione: ChatGPT si dimostra utile nel rispondere a domande relative agli algoritmi o alle tecniche di Data Science in uso, soprattutto in materia di iper-parametri per i modelli di Machine learning e, in particolare, quando si lavora con i framework più popolari la cui parametrizzazione può appiattire la competitività
- approfondimento: un data scientist può usare ChatGPT per identificare tendenze in un set di dati o trovare correlazioni tra variabili diverse
- pre-elaborazione: ChatGPT può fornire consigli sulle tecniche per la gestione dei valori mancanti, il ridimensionamento delle funzionalità e anche per la data augmentation
- codifica: allo stesso modo, ChatGPT può creare porzioni di codice utili all’advanced analytics
Utilizzando ChatGPT i data scientist possono risparmiare tempo e prendere decisioni più informate durante l’intero processo di sviluppo del progetto di Data science.
Come la Data science può migliorare le capacità di ChatGPT
La versione breve: i data scientist possono pensare fuori dagli schemi, ChatGPT non esce dai limiti tracciati dai dati di addestramento. I data scientist confrontati con problemi complessi tendono a cercare soluzioni alternative e a loro modo creative. La Data science richiede anche intuizione, etica e, più in generale, intelligenza emotiva. Tutte doti che a ChatGPT sfuggono e anche laddove, come nel caso dell’etica, ne ha una timida parvenza, questa è riconducibile all’addestramento con il quale sono stati esclusi termini inadatti e argomenti ritenuti inopportuni.
L’uomo, il data scientist, può contribuire ad arricchire i dataset a disposizione di ChatGPT affinché i confini all’interno dei quali si muove siano più ampi, benché l’emulazione delle doti tipiche dell’uomo sia materia a tratti contorta e che ancora oggi non appartengono alle Intelligenze artificiali.
Ciò che invece la Data science può fare nell’immediato è impegnarsi affinché ChatGPT possa restituire risultati in linea con le norme etiche.
Il ruolo che giocano intuito e creatività nell’ambito della Data Science è argomento datato, come dimostra un articolo dell’Harvard Business Review pubblicato nel 2013, l’avvento di ChatGPT crea però un interscambio certamente più attuale.
L’importanza della Data science nell’addestramento di ChatGPT
L’addestramento di ChatGPT avviene per lo più tramite dati disponibili sul web. Una scelta in qualche modo obbligata tanto per raggiungere una trasversalità d’uso capace di raggiungere la platea più ampia di persone possibile, quanto per permetterne l’impiego in una quantità di attività correlate. Il fine-tuning può però essere demandato alle imprese che usano ChatGPT al proprio interno, addestrandola su dataset proprietari.
Ritorna l’aspetto simbiotico tra Data science e ChatGPT. La City University di Hong Kong ha dimostrato in modo empirico che ChatGPT può fare Data Science con dei limiti evidenti ed è, nel percorso a ritroso, che tali muri possono essere scavalcati.
Infatti, la Data science può contribuire a creare dataset specialistici che sono le fonti di riferimento a cui attinge ChatGPT, potenziando così il lavoro dell’uomo e sempre rimanendo all’interno dei confini imposti dai dati di addestramento, pure tenendo conto dei limiti che le AI generative palesano.
Data Science e ChatGPT: un binomio vincente per l’elaborazione dei dati complessi
Al fianco di quella prettamente tecnico-tecnologica siede la questione dell’impiego perché, se ChatGPT fosse in grado di elaborare dati complessi nell’ambito della Data science, tra le professioni minate dalle AI figurerebbe anche quella del data scientist.
La questione non si pone perché la complessità del lavoro del data scientist non è nelle corde di ChatGPT che, tuttavia, svolge alcuni compiti al pari dell’uomo (si pensi alla scrittura di codice) e in tempi più brevi. Un po’ poco per mettere in discussione le capacità astrattive dell’operatore umano.
È però vero che, in sinergia, i due emisferi possono fare molto uno per l’altro, soprattutto lavorando su dataset proprietari.
La Data science sta migliorando l’accuratezza di ChatGPT nell’interpretazione dei dati
Che la Data science stia migliorando l’accuratezza con cui ChatGPT interpreta i dati è tema che rinfranca la validità della vicendevolezza, perché ChatGPT dà indicazioni preziose ai data scientist in merito alle tecniche da usare per aumentare la propria capacità di interpretare i dati.
Ciò avviene soprattutto grazie a procedure di data augmentation, ossia l’aggiunta di copie lievemente modificate di dati già esistenti per regolare l’overfitting durante l’addestramento di modelli di Machine learning. L’overfitting si registra quando un modello complesso si adatta ai dati perché dotato di un numero elevato di parametri rispetto alla quantità di questi ultimi.
Una sinergia che nasce da una simbiosi oggetto di uno studio a più mani, curato e redatto da scienziati provenienti da diverse università cinesi e americane. Una ricerca che mira a osservare l’impiego di ChatGPT per la data augmentation la quale, a sua volta nei dataset proprietari, aiuta ChatGPT a contestualizzare meglio i dati, restituendo risultati più accurati e centrati rispetto all’argomento trattato.
Una sinergia per l’analisi predittiva dei dati
Simbiosi e sinergia sono parole chiave nel rapporto tra Data science e ChatGPT. L’uso di quest’ultima nelle analisi predittive giova in termini di accuratezza di dati ma anche nella semplificazione dei flussi di lavoro. Le capacità di apprendimento automatico di ChatGPT sono un toccasana per assistere nella creazione di modelli di previsione basati su dataset proprietari.
Un quadro ampio nel quale svettano alcuni compiti demandabili alle peculiarità di ChatGPT, tra i quali:
- il suggerimento di metodi e funzionalità per la creazione e l’analisi di un modello
- il suggerimento di metodi per arginare i problemi relativi alla qualità dei dati
- il suggerimento degli strumenti più adatti all’analisi dei dati in un contesto specifico
Tutto ciò si trasforma nella possibilità di prendere decisioni precise, consapevoli e mirate.
Nuove prospettive nell’interpretazione dei dati
Tiriamo le somme e giungiamo alle conclusioni del caso. L’uomo ha doti interpretative che le Intelligenze artificiali ancora non hanno e queste ultime hanno un tasso di precisione e rapidità a cui l’uomo non può tendere.
Gli effetti sinergici che ne derivano suggeriscono le prospettive, ossia le necessità di ottenere vantaggi specifici dall’uso dei dati e utilizzare modelli che tengano conto – per quanto possibile – della creatività dell’uomo.
Materia impervia e multidisciplinare a cui la letteratura di settore fa riferimento usando il termine “analisi creativa dei dati”, ossia un’analisi dei dati tradizionale mediata e miscelata con le abilità del pensiero astratto. Questo può dare vantaggi di diverso ordine, tra i quali spiccano:
- la scoperta di nuove correlazioni tra dati e nuove tendenze che, unite, possono condurre a nuove strategie di business e financo a nuove possibilità di business, con lo sviluppo di nuovi prodotti o servizi
- la risoluzione di problemi complessi mediante logiche innovative, persino rischiose o eretiche secondo i parametri del mercato di riferimento delle imprese
- una maggiore competitività dettata anche dalla capacità di prendere decisioni consapevoli, innovative e mirate anche a segmenti di mercato parzialmente o del tutto inesplorati.
Più facile a dirsi che a farsi, certo, ma la diffusione della cultura del dato deve portare a una differenziazione nella capacità di farne uso, altrimenti la competitività delle imprese rischia di entrare in una fase di appiattimento. Se le imprese attive in un settore prendono tutte le medesime decisioni tirando le medesime conclusioni sulla scorta dei dati in loro possesso, ci si espone a una flessione nel potenziale innovativo.

















