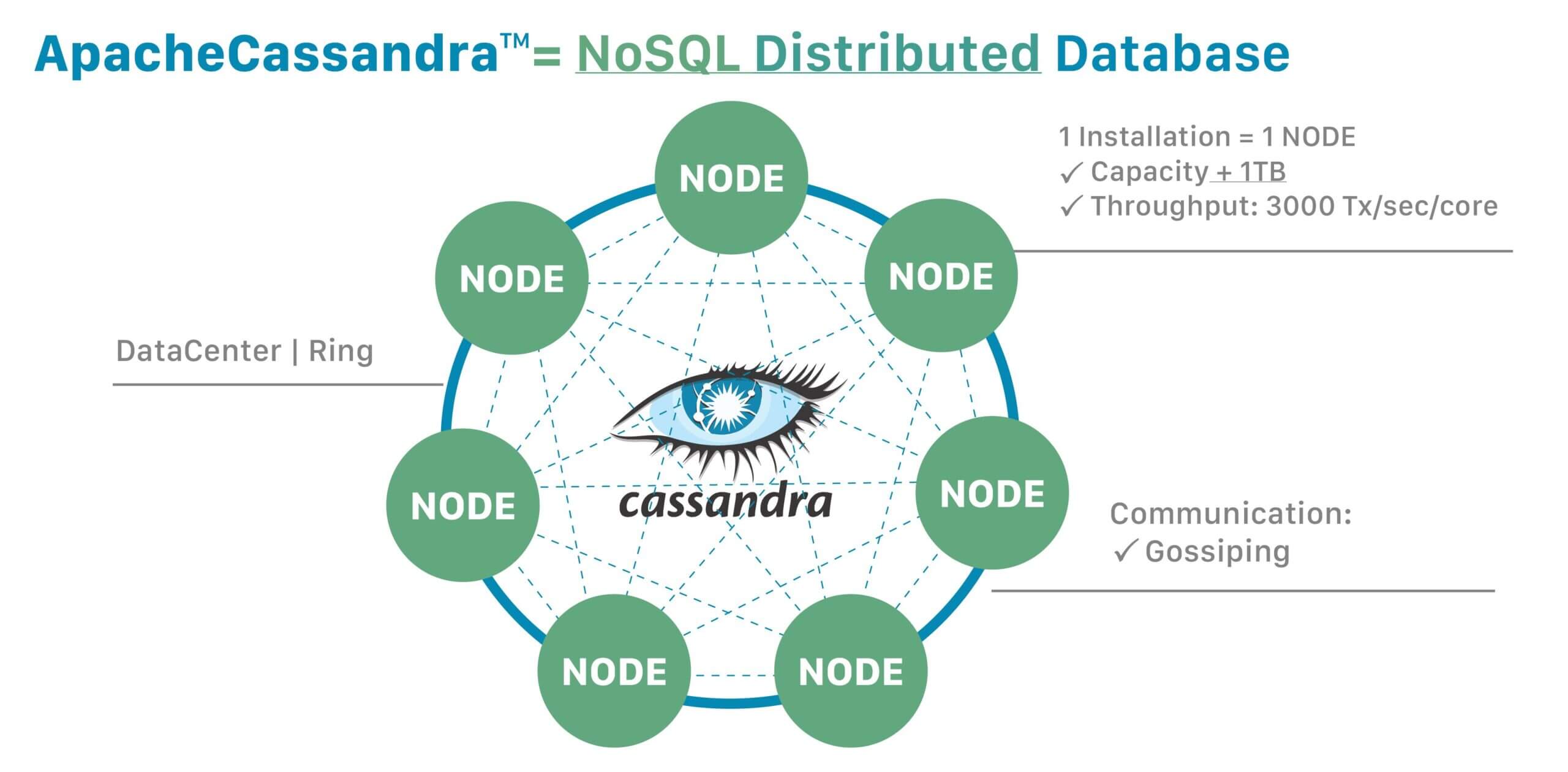
Apache Cassandra è un DBMS, un sistema di gestione di database Open source NoSQL e, come tale, predisposto per i Big data.
approfondimento
Come Cassandra domina i Big data: come funziona il DB NoSQL
Un DBMS Open source distribuito particolarmente indicato per la gestione dei Big data. Tra i punti di forza la scalabilità e l’affidabilità, sostenuta da un approccio ridondante di replica dei dati che, di norma, è una spina nel fianco dei database relazionali
Pubblicato il 23 gen 2024
Continua a leggere questo articolo

Canali
Speciale Digital Awards e CIOsumm.it
Tutti
Update
Keynote
Round table
Filtra per topic















