
In precedenza noto come Amazon Elastic MapReduce, Amazon EMR è una piattaforma che esegue facilmente carichi di lavoro di big data.
L’obiettivo è l’elaborazione e l’analisi di grandi moli di dati. Ecco cos’è e come effettua il data processing.

Indice degli argomenti
Cos’è Amazon EMR
Amazon EMR è una piattaforma di cluster gestita che facilita l’esecuzione di framework di big data, come per esempio Apache Hadoop e Apache Spark, AWS. Esegue Apache Spark, Hive, Presto, oltre ad altri carichi di lavoro di big data.
Grazie a questi framework e alle relative iniziative open source, permette l’elaborazione dei dati al fine di analizzare ed effettuare carichi di lavoro di business intelligence.
Amazon EMR permette inoltre di trasformare e spostare grandi moli di dati all’interno e all’esterno di altri datastore e database AWS, inclusi Amazon Simple Storage Service (Amazon S3) e Amazon DynamoDB.

Come funziona
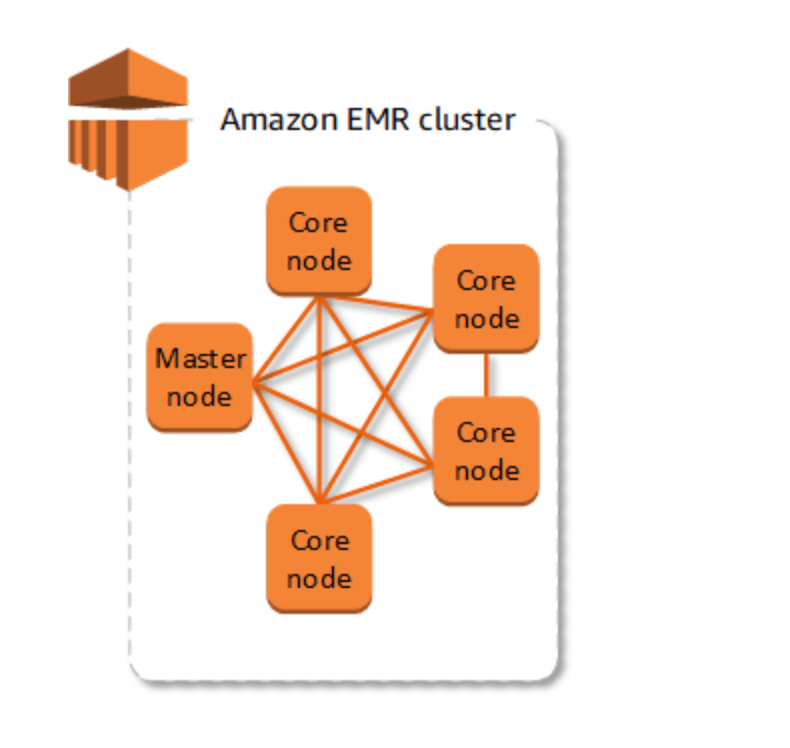
Il cluster è l’elemento centrale di Amazon EMR. Si tratta di una raccolta di istanze Amazon Elastic Compute Cloud (Amazon EC2), dove ciascuna istanza nel cluster rappresenta un nodo.
Il nodo gioca un ruolo all’interno del cluster, noto come tipo di nodo. Amazon EMR installa inoltre differenti componenti software su ciascun tipo di nodo, investendo ogni nodo di un ruolo in un’applicazione distribuita come Apache Hadoop.
I tipi di nodi in Amazon EMR sono: nodo primario; quello principale; nodo di task. Vediamoli nel dettaglio.
Il nodo primario è in grado di gestire il cluster attraverso l’esecuzione di componenti software. Lo scopo è quello di coordinare la distribuzione di dati e attività fra gli altri nodi al fine dell’elaborazione. Traccia inoltre lo stato delle attività, monitorando l’integrità del cluster. Ogni cluster è dotato di un nodo primario, per creare un cluster a nodo singolo con soltanto il nodo primario.
Invece il nodo principale vanta componenti software per l’esecuzione di task e memorizzazione dati in Hadoop Distributed File System (HDFS) sul cluster. I cluster multi-nodo hanno almeno un nodo principale.
Il nodo di task può contare su componenti software che eseguono solo le attività senza la memorizzazione dei dati in HDFS. I nodi di task sono opzionali.
L’invio di lavori al cluster
Nel corso dell’esecuzione di un cluster su Amazon EMR, variano le opzioni sul modo di specificare il lavoro da svolgere.
Bisogna offrire la definizione intera e completa del carico di lavoro in funzioni specifiche come passaggi durante la creazione di un cluster. Ciò è dedicato ai cluster che elaborano una stabilita quantità di dati e poi concludono alla fine dell’elaborazione.
Occorre realizzare un cluster di lunga durata, usando la console Amazon EMR, l’API di Amazon EMR o la AWS CLI per l’invio di fasi contenenti uno o più processi.
Una volta creato un cluster, è possibile connetterlo al nodo primario e ad altri nodi tramite SSH e sfruttare le interfacce che le applicazioni installate offrono, per eseguire attività e inviare interrogazioni, via script o interattivamente.

Eseguire analisi dei big data
Amazon EMR è un servizio gestito in grado di far girare Apache Hadoop e Spark velocemente, riducendo i costi e facilmente. L’obiettivo è quello di processare vaste quantità di dati.
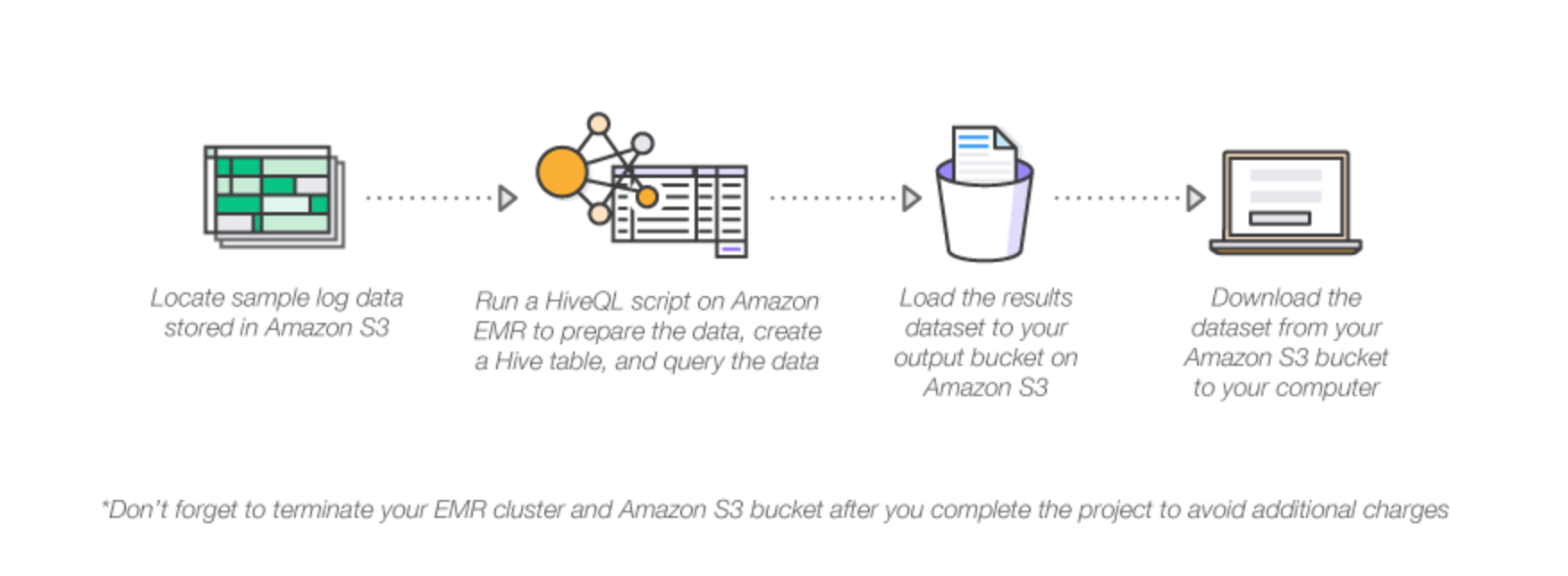
Amazon EMR inoltre supporta potenti e comprovati strumenti Hadoop come Presto, Hive, Pig, HBase eccetera. In questo progetto, è possibile sviluppare un cluster Hadoop completamente funzionale, pronto per analizzare i log data in pochi minuti.
Basta avviare il lancio del cluster Amazon EMR, per poi usare lo script HiveQL per elaborare il campione di log data archiviati in un Amazon S3 bucket. HiveQL, è un linguaggio di scripting SQL-like per data warehousing e analisi. Dopo è possibile utilizzare una configurazione simile per analizzare i log file.
Elaborare flussi di dati
Amazon EMR facilita la realizzazione e il funzionamento degli ambienti e delle applicazioni per big data. si distingue per il provisioning, scaling gestito e riconfigurazione semplificati dei cluster. Invece, EMR Studio per lo sviluppo collaborativo.
In pochi minuti permette l’avvio di un cluster EMR, senza dover allocare un’infrastruttura né impostare, configurare o eseguire l’ottimizzazione dei cluster. Permette dunque ai tuoi team di focalizzarsi sullo sviluppo di applicazioni di big data differenziate.
Permette il ridimensionamento facile di risorse, come la policy di scaling gestito EMR, per soddisfare le necessità di business. Consente al cluster EMR la gestione automatica delle risorse di calcolo per venire incontro alle esigenze d’uso e di performance. Consente di ottimizzare l’impiego dei cluster, riducendo i costi.
EMR Studio è un ambiente di sviluppo integrato (IDE) che facilita sviluppo, visualizzazione e debug di applicazioni di data engineering e data science scritte in scritte in R, Python, Scala e PySpark per i data scientist e i data engineer.
Con alta disponibilità con un clic, permette di configurare l’alta disponibilità per applicazioni multi-master come YARN, HDFS, Apache Spark, Apache HBase e Apache Hive con un singolo clic.
Attivando il supporto multi-master, EMR imposterà le applicazioni per assicurare elevata disponibilità. Nel caso di errori, avvierà in automatico il processo di failover su un master affinché l’attività del cluster non subisca interruzioni e si posizioni i nodi master in rack distinti, abbassando il rischio di errori simultanei. Il monitoraggio degli host permette di rilevare gli errori e quando si riscontrano problemi, si allocano nuovi host, aggiungendoli in automatico al cluster.

Lo scaling gestito EMR
Lo scaling gestito EMR ridimensiona automaticamente il cluster, al fine di migliorare le prestazioni, risparmiando sui costi. Inoltre è possibile specificare i limiti di elaborazione minimo e massimo per i cluster. Amazon EMR li ridimensionerà in automatico, in modo da ottenere prestazioni e utilizzare le risorse migliori. Inoltre, lo scaling campiona di continuo i parametri chiave legati ai carichi di lavoro in esecuzione sui cluster.
La riconfigurazione dei cluster in esecuzione
Riconfigurare i cluster in esecuzione permette di modificare la configurazione delle applicazioni in esecuzione sui cluster EMR, fra cui Apache Hadoop, Apache Spark, Apache Hive e Hue, senza il riavvio del cluster. Permette di modificare le applicazioni senza necessità di arrestare o ricreare il cluster. Amazon EMR applicherà inoltre le nuove configurazioni, riavviando agevolmente l’applicazione ri-configurata. La Console, l’SDK o l’interfaccia a riga di comando permettono di applicare le configurazioni.
















